



Video Understanding and Facebook’s AI Strategy

Facebook has quietly grown to be a video platform. It has the largest user-generated video content outside YouTube. Each day, people view Facebook videos for 8 billion times and spend 100 million hours watching (with 20 percent of videos live streamed). Facebook users can upload videos, stream live videos on their pages, and have video chats with their friends. Recently, Facebook launched a new feature that lets people do video chat in Facebook Groups.
As a social network giant of 2.2 billion users, Facebook needs to serve the users fast and effectively. This means being able to quickly process users’ videos with correct tags, search, and further to understand: What are people talking about? What videos are they leaving comments? With that knowledge, Facebook can build algorithms to better connect people, serve ads and do more.
Given the large volume of videos and speed of consumption, Facebook needs to find a scalable and automatic way to process videos. This is where artificial intelligence can help. But video understanding is still new for AI. While deep learning has achieved near perfect accuracy in image recognition and speech processing, video understanding is still far from ideal. Here we user the term “video understand” in a broad sense that includes tagging or classifying videos (“dancing” vs “running”), understand events inside a video (“child fell”,”ball kicked in”), and tracking people or animals inside a video.
Facebook has devoted a significant amount of resources to video understanding.
An AI Powerhouse
Facebook has been building its AI arsenals, and become a dominant player in AI research and development. In addition to a large research lab that was previously led by deep learning pioneer Yann LeCun (until early this year), Facebook also has a large applied machine learning division. It hired away top computer vision researchers from Microsoft, including Kaiming He who invented ResNet (Residual Network) that won the ImageNet competition in 2015. ResNet is faster and more accurate than other neural networks and has been powering Facebook’s image processing products. Facebook also hired away some leading NLP researchers from Google such as Tomas Mikolov who invented Word2Vec. Today Facebook has one of the most active researcher groups in language, speech and computer vision.
In the the best computer vision conference CVPR 2018, Facebook researchers presented more than 30 papers, among them 10 are on video understanding.
The Challenges of Video Understanding
Videos are sequences of image frames. Video analysis processes images in a sequential manner. The size of video is much larger than an image. A 1-minute video contains more than 1400 pictures.
The natural way of processing video is borrowing methods from image processing. In 2014, Fei-Fei Li and fellow researchers at Stanford and Google applied Convolutional Neural Networks (CNN) that was successful in image recognition to videos. It had significant performance improvements compared to feature-based baselines.
However, we can do better than just applying CNN. If we model time as 1 dimension, and each picture as a 2D image, then a video is a 3D cube. This combination of space and time is called spatiotemporal property. In 2015, Facebook AI researchers invented 3D CNN, which outperformed state-of-the-art methods on four different benchmarks — action recognition, action similarity labeling, scene recognition, and runtime analysis. The project was later open sourced.
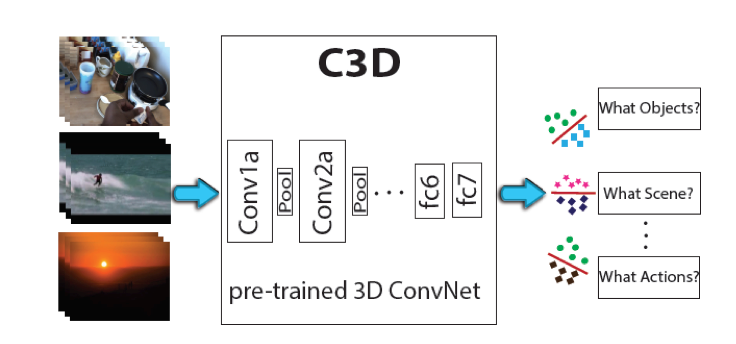
However, the time dimension is slightly different from the other two spatial dimensions. There are dependencies between time points. Therefore it’s better to separate these two types of properties. Facebook researchers invented (2+1)D, where the images are processed first, and the time dimension is added. This algorithm runs on a ResNet. Thus it is called R(2+1)D. They achieved state-of-the-art accuracy with only one-third of computing time of 3DCNN.
Incorporating Audio Information
Another complication of videos is the sound in the video. The audio information is essential for a video, particularly for speeches and conversations. Potentially we can create multi-modal machine learning methods. But in reality, a video might have long segments of boredom and a small part of useful information. Creating a text description and titles for such a video is not easy.
Tracking Objects inside Video
Many video datasets are centered around understanding what people are doing, or actions of people. Pose estimation, a computer vision problem that tracks the key points of a person, is a step towards understanding what activities people are doing.
Facebook researchers discovered that Mask R-CNN, a deep learning method developed by Facebook Researcher Kaiming He for object instance segmentation, can be applied to video-based segmentation and pose estimation and produce promising results.

But what if the problem is estimating and tracking human body key points in a multi-person video? Facebook researchers last year proposed a novel video pose estimation formulation, 3D Mask R-CNN, that produces key points of people in short clips, and perform lightweight optimization to link the detections over time. The approach won the ICCV 2017 PoseTrack key point tracking challenge.
Internal large-scale computing platform
To support video research and development, Facebook has built an internal platform called Lumos. Lumos provides a simplified process for developers to train AI models on images and videos. First is the data. Many new tools on Lumos around data annotation can do image clustering. Second is the model. Developers can select off-the-shelf deep neural networks from Lumos and integrate particular features, like image feature and text features, into the model.
Lumos runs on billions of images and has more than 400 visual models for purposes of objectionable-content detection and spam fighting to automatic image captioning.
Active Support for Open-source Community
Open-source datasets have been the fuel driving AI innovations. While there are many datasets in image and speech, video dataset is somehow in short supply.
Facebook released 2 video datasets to the public in October 2017. The Scenes, Objects, and Actions dataset (SOA) provides developers with a massive set of videos that contain multiple labels indicating what’s going on inside them. Each video was tagged by humans on where a video is taking place, what is in it, and what is going on in the scene.
The Generic Motions dataset includes a set of GIFs that associate motions with many different kinds of objects beyond humans, like a polar bear sliding or a cat falling. The data pieces are very small GIFs that requires only small amounts of computing.
In 2018, Facebook opened up the research platform Detectron that contains state-of-the-art object detection algorithms, such as Mask R-CNN, to the public. Users can use this platform to train their video models. Once trained, these models can be deployed in the cloud and on mobile devices, powered by the highly efficient Caffe2 runtime.

Facebook is at the forefront of video research and development.
In the upcoming AI Frontiers Conference held from November 9 to November 11, Matt Feiszli, Facebook Research Manager, will talk about Facebook’s work on video understanding.
Feiszli leads computer vision effort at Facebook. He was previously Senior Machine Learning Scientist at Sentient Technologies and also spent four years at Yale University as Gibbs Assistant Professor in mathematics. He earned his undergraduate degree at Yale University and received Ph.D. of Applied Mathematics from Brown University.

AI Frontiers Conference brings together AI thought leaders to showcase cutting-edge research and products. This year, our speakers include: Ilya Sutskever (Founder of OpenAI), Jay Yagnik (VP of Google AI), Kai-Fu Lee (CEO of Sinovation), Mario Munich (SVP of iRobot), Quoc Le (Google Brian), Pieter Abbeel (Professor of UC Berkeley) and more. For media inquiry and ticket information, please contact us at: info@aifrontiers.com