



How to Build a Household Robot: Pieter Abbeel’s Story

Pieter Abbeel is on a quest. He wants to make a robot that can cook, clean up the room, make the bed, take out the trash, and fold the laundry.
The UC Berkey Professor started this quest since he was a graduate student in Andrew Ng’s group at Stanford University back in 2002. At that time, there was no robot for him to play with. He started with self-driving cars and helicopters.
In 2004, Abbeel published the paper Apprenticeship Learning via Inverse Reinforcement Learning. He proposed a new approach to train robots by observing an expert performing a task. He showed the feasibility of this approach in a simulation of self-driving cars. The paper is later regarded as one of his most important papers.
He then applied apprenticeship learning to helicopter control. Together with fellow student Adam Coates and his advisor Andrew Ng, Abbeel successfully trained a helicopter to perform an airshow without human supervision.
Abbeel became an Assistant Professor at UC Berkeley after receiving his Ph.D. in 2008. For the next 10 years until today, he has devoted himself fully to his true passion: Building a household robot .
A household robot should be versatile enough to do different chores. You don’t want to employ 5 different robots — one does cooking, one does laundry, one does dish washing, and so on . Even if your house is large enough for 5 specialized robots, you may want a robot to do other things: Picking up clothes on the floor, fetching a cup of coffee for you, opening the window, and so on.
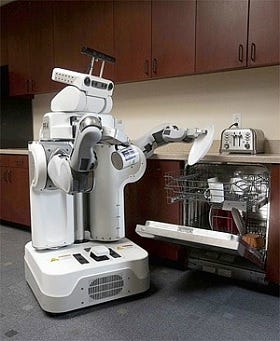
How do we build a general-purpose robot? Today’s robot can barely do one task well. It takes many hours of training for a robot to learn to move its arm in the right direction to pick up a cup.
Such difficulty does not prevent Abbeel from dreaming big. His first idea was using “imitation.” A person does a task, and the robot repeats it. This would save training time, and maybe allow the robot to do additional jobs.
In 2010, Abbeel created BRETT (for “Berkeley Robot for the Elimination of Tedious Tasks”), adapted from a Willow Garage PR2 robot that comes with cameras and grips. Following a set of rule-based instructions, BRETT became the first robot that can fold piles of towels. By doing this, Abbeel demonstrated that the hardware problem of a household robot can be solved.

He then turned his attention to the software problem. How does a robot learn to do a task? How does a robot learn to do multiple jobs?
Reinforcement Learning
Abbeel has been captivated by reinforcement learning (RL), which is a machine learning method that teaches an agent to do the right action through reward and punishment. This learning method assumes the agent interacts with its environment that gives the robot feedback for its actions. A simple example is pulling the arms of several slot machines. Different slot machines give you different payoffs. After a while, you learn to pull the arm that gives you the highest payoff. This is called the multi-armed bandit problem. A more complex example is playing a video game. By trying on different actions such as shooting and ducking, you get different scores and learn to play the game better.
Reinforcement learning is useful for training robots, as a robot needs to interact with the world by moving, grasping, folding, or doing other actions. If the robot receives the reward, it can do that action more often or more correctly.
Abbeel applies reinforcement learning in almost all his research. Take an example of BRETT. Its onboard camera can pinpoint the objects in front of it, as well as the position of its own arms and grips. Through trial and error, it learns to adjust its position of the hammer claw and maneuver the angle to the right place to pull out the nail.
Deep Reinforcement Learning
The drawback of reinforcement learning is that the environment is complex. To describe a task, a room, or a game, we have to enumerate all the positions, all different angles, and different situations. If we call each unique situation a state, the number of states will be in thousands or tens of thousands for a simple task.
How can the robot quickly summarize the current state and learn fast? The solution came from deep learning, which became popular after 2012 when it was shown to be effective in classifying images in the “cat” paper (presented in ICML 2012) and AlexNet paper (presented in NIPS 2012). Deep learning takes the raw image pixels and generalizes them to a few classes. Thus it frees us from manually identifying the important “features” in a picture or in the environment.
It is therefore natural to apply deep learning to a robot that interacts with its environment. Here deep learning is used to summarize the states. The robot can still use reinforcement learning to decide on the actions. Combining deep learning with reinforcement learning leads to the success of playing Atari game in 2013 and the Go game against human masters in 2016. The field of deep reinforcement learning was born.
Abbeel embraced deep reinforcement learning wholeheartedly. He was so enthusiastic about it that he gave a tutorial called Deep Reinforcement Learning through Policy Optimization at NIPS 2016. It is still one of the most popular tutorials on deep reinforcement learning.
While deep reinforcement learning teaches a robot to do a task well, it does not generalize to multiple tasks. In other words, robots learn to do to a five-second action. But a five-second skill is something very different from a day-long skill, which is needed for a robot to roam in a house, performing different chores. This is where meta-learning is necessary.
Meta-Learning: Generalize learning for a new task
Meta-learning is learning from multiple tasks and applying the learning to a new task. It is also called “learning to learn”.
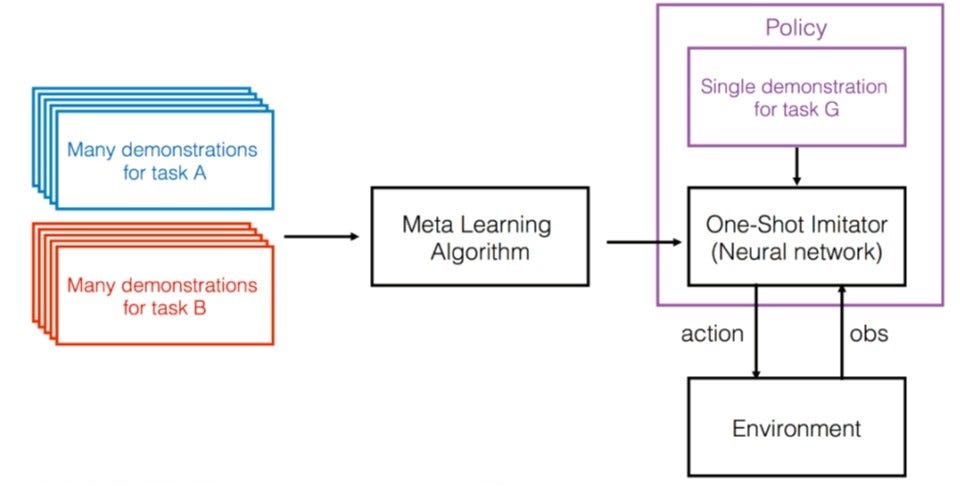
In NIPS 2017, Abbeel and fellow researchers at OpenAI and UC Berkeley presented the paper One-Shot Visual Imitation Learning via Meta-Learning, which combines meta-learning with one-shot learning (where the agent only get 1 example), With a meta-learner trained in multiple tasks, this system just needs to observe 1 demonstration, can then takes produces the right action for a new task.
Abbeel and his group further invented the Simple Neural Attentive Learner (SNAIL) and presented it in ICLR 2018. This is a meta-learner implemented in 1 single deep neural network. This network combines sequence to sequence learning with soft attention, which allows the robot to remember the context of different tasks.
Other Research Activities
Being a UC Berkeley Professor, Pieter Abbeel enjoys the privilege of getting talented and hardworking graduate students to work with him. Today he is supervising 25 Ph.D.s and postdocs, along with 25 undergraduate students. Like a general, Abbeel is leading his large troop to charge the hills of the robotics height. His troop fans out from different directions to scale the mountain. Here are the other researches his team is working on:
- Lifelong learning: A robot needs to continuously adapt to different tasks and different situations (generated by another learning agent). It’s applying meta-learning sequentially and generalize well. In experiments with two spider robot fighting again each other, they show that the continuously adaptive robot wins in the end. The most recent paper is written by Maruan Al-Shedivat of CMU, co-authored with people in OpenAI where Abbeel is affiliated.
- Leverage simulation to train a robot.
- Using past experience: This method is called Hindsight Experience Reply (HER). Instead of waiting until agent reaches the final goal to update the model once, we can propagate the reward back to all the actions in the past, and create a replay. In a replay, each intermediate reward is treated as a final reward. Thus we can update the learning function in each intermediate step (state) and learn faster. This reduces the data required for learning.
Pieter Abbeel is on his way to his dream: Create a true household robot.
Maybe in the not-too-distant future, a robot at your home puts the dishes away and cooks meals for you. When you show your appreciation, the robot shakes his head and smiles, “No need to thank me. I am just an apprentice of Pieter Abbeel.”

Pieter Abbeel will speak at AI Frontiers Conference’s Robot session on Nov 10, 2018 in San Jose, California. Join us at aifrontiers.com.
AI Frontiers Conference brings together AI thought leaders to showcase cutting-edge research and products. This year, our speakers include: Ilya Sutskever (Founder of OpenAI), Jay Yagnik (VP of Google AI), Kai-Fu Lee (CEO of Sinovation), Mario Munich (SVP of iRobot), Quoc Le (Google Brian), Pieter Abbeel (Professor of UC Berkeley) and more. For media inquiry and ticket information, please contact us at: info@aifrontiers.com