



An Unassuming Genius: The Man behind Google’s AutoML

Slim, quiet, and wearing a pair of thick glasses, Quoc Le does not strike you as someone who is leading a revolution in the AI field.
In 2011, Le co-founded Google Brain, together with his Ph.D. advisor Andrew Ng, Google Fellow Jeff Dean and Google Researcher Greg Corrado. The goal was exploring deep learning in the context of Google’s gigantic data. Before that, Le has done some pioneering work at Stanford on unsupervised deep learning.
In 2012, Le published a paper (presented at ICML) that started the keen interest on deep learning: He has developed a deep neural network model that can recognize cats based on 10 million digital images from Youtube, as well as over 3,000 objects in the ImageNet dataset. The giant system consists of 16,000 machines and one billion synapses, 100 times larger than anyone who had ever tried. Le’s paper was followed by the AlexNet paper later that year, and the whole field of deep learning started to generation traction.
While the unsupervised learning approach was later proved to be impractical for commercial use — at least during that period — Le said in a 2015 Wired interview that “it would be wonderful if we could have an algorithm that can discover that — that can learn in the same way — because more practically, we have much more unlabeled data than labeled data.”
Sequence to Sequence Learning
After formally joining Google as a research scientist upon his graduation in 2013, Le soon achieved stunning breakthroughs in machine translation, one of the most active research areas in the machine learning community.
To achieve this result, he has to move beyond the deep learning methods that worked well with images and speech, which can be analyzed with fixed-size input. With natural languages, the length of the sentence varies and the order of words matters.
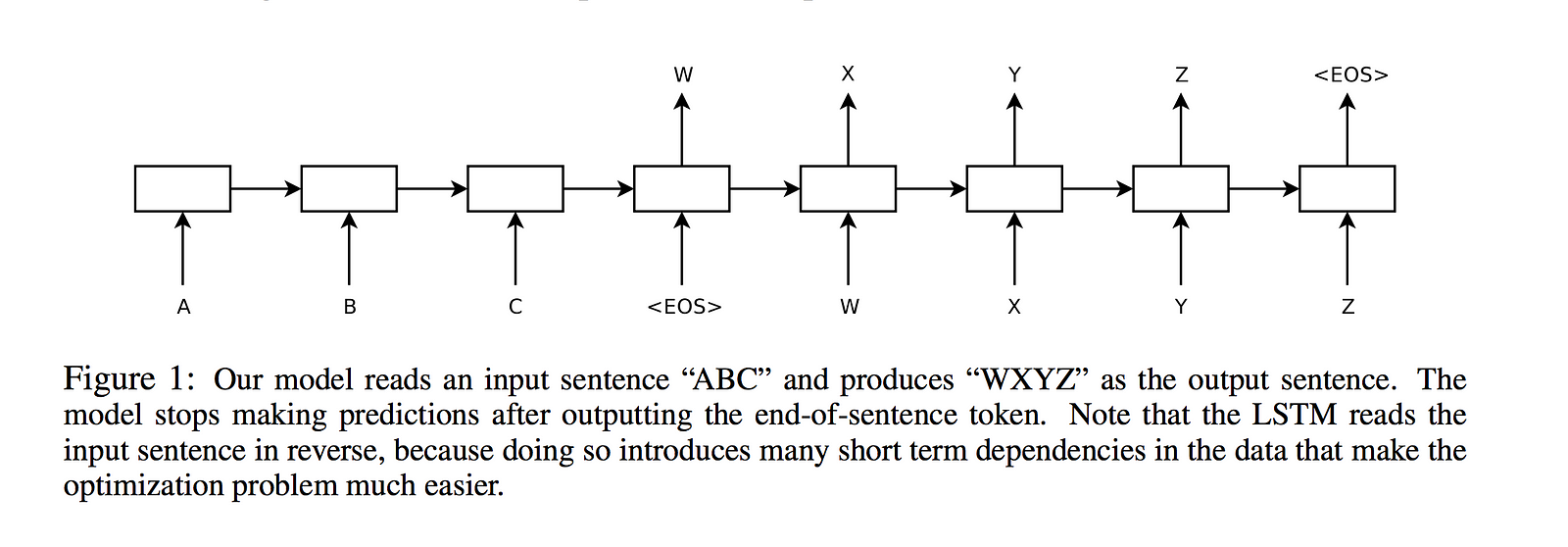
In 2014, Le proposed sequence to sequence (seq2seq) learning with Google Researcher Ilya Sutskever and Oriol Vinyals. It is a general-purpose encoder-decoder framework that trains models to convert sequences from one domain to another, such as sentences between different languages.
The seq2seq learning requires fewer engineering design choices and allows Google translation system to efficiently and accurately work on very large datasets. It is mainly used for machine translation systems and is proved to be applicable in a broader range of tasks, including text summarization, conversational AI, and question-answering.
Le further invented doc2vec, an unsupervised algorithm learns fixed-length feature representations from variable-length pieces of texts, such as sentences, paragraphs, and documents. Doc2vec is an extension of word2vec, which was presented in 2013 by Google fellow Tomas Mikolov. The idea is that each word can be represented by a vector, which can be automated learn from a collection text. Le added paragraph vector so the model can generate a representation of the document, regardless of its length.
Le’s research efforts paid off. In 2016, Google announced Neural Machine Translation system, which uses AI to learns over time to create better and more natural translations.
In 2015, Le made the MIT Technology Review’s “Innovators Under 35” list in the Visionaries category, for aiming “make software smart enough to assist people in their everyday lives feels pretty good.”

AutoML: Neural Network Learns to Improve Itself
Training a deep neural network requires a large amount of labeled data and back-and-forth experiments: You choose an architecture, build hidden layers, and adjust weights based on outputs. For people with limited machine learning expertise, the training process is somehow painstaking and time-consuming.
In 2016, Le and another Google fellow Barret Zoph proposed neural architecture search. They use a recurrent network to generate the model descriptions of neural networks and train this RNN with reinforcement learning to maximize the expected accuracy of the generated architectures on a validation set.
The new approach can help researchers design a novel network architecture that matches the best human-invented architecture in test set accuracy on the CIFA-10 dataset. One year later, Le and Zoph took their study to the next level by proposing NASNet-A, a transferable architecture for large-scale image datasets.
On the left is aneural net designed by human experts. On the right is a recurrent architecture created by our method.
Le’s research lays the groundwork for AutoML, a suite of Google products designed for developers who have limited machine learning expertise and resources. At an early stage though, AutoML is now solving real-life problems: a data scientist used AutoML to build a model that identifies the restaurant based on noodle images, with almost 95 % accuracy; a Japanese developer built a model that can classify images with its brand name, with AutoML.
Google launched AutoML Vision earlier this year. Last month at Google’s Cloud Next conference, the company released tools of translation and natural language.
For the last sixyears, Le has stayed at the forefront of deep learning development. The 36-year-old Google research scientist now is poised to take deep learning to the next level.
At the upcoming AI Frontiers Conference held from November 9 to November 11, which will assemble luminary AI Speakers from OpenAI Founder Ilya Sutskever to robotics professor Pieter Abbeel, Le will speak of the development of AutoML and his vision to machine learning.
We are eager to hear Le’s vision for the future of machines that learn to improve themselves. Would machine replace data scientists eventually? This is a question that awaits answers.
