



An Inside Look Into Adobe’s AI Effort
I remember the first time I saw photoshop more than 10 years ago: My designer was trying to modify a picture for our website, to match the color of our website — Green. He clicked on the blue sweater of the woman in the picture (and then clicked on some color on the side), then magically that whole sweater turned into green while other parts of the pictures kept the same. I was awed.
Over 90 percent of the world’s creative professionals use Photoshop, an Adobe product. Over 12 million people subscribe to Adobe’s Creative Cloud, the suite of Photoshop, Premiere Pro, After Effects, etc. Each day Adobe receives hundreds of millions of highly-produced images and videos from all over the world. Leveraging such a massive volume of data using artificial intelligence can help Adobe better understand what their artists and designers customers really need.
Adobe Sensei
Adobe’s take on artificial intelligence started in fall 2016 when the company announced its Sensei AI platform devoted to artists and designers by providing AI-empowered creation tools. FYI, Sensei is a Japanese term known as a teacher or an instructor.
Adobe CTO Abhay Parasnis described Sensei as a set of AI features incorporated into Adobe’s services such as Premiere and Photoshop. He once told TechCrunch that “When one of the very best artists in Photoshop spends hours in creation, what are the other things they do and maybe more importantly, what are the things they don’t do? We are trying to harness that and marry that with the latest advances in deep learning so that the algorithms can actually become partners for that creative professional.”

Adobe CTO Abhay Parasnis
Adobe Sensei provides 4 primary services:
\1. Understanding digital content such as images, videos, animations, and illustrations;
\2. Adding AI algorithms to accelerate the design process;
\3. Delivering the appropriate digital content to targeted customers;
\4. Building custom workflows and applications as an open framework;
The creative intelligence is the Adobe Sensei’s call that drives artists and designers on board. It can enable more realistic 3D designs by using AI to set background lighting and correct perspective to match the foreground image and bring characters to life by synchronizing the character with a human’s movement, voice, facial expression, and even the mouth shapes.
To polish its professional editing tools, Adobe Sensei recently rolled out some novel features and additions at the IBC 2018 conference in Amsterdam, such as a better color management in video editing applications Premiere Pro and After Effects, a noise clean up tool to remove background noise and improve audio quality, and an upgraded Character Animator.
Divya Jain’s new journey with Adobe
Adobe has assembled some of the best graphic designers and imagery developers. However, to take its AI efforts to the next level, the company needs AI experts who master machine learning algorithms and data science.
This May, Divya Jain, a well-known AI & data mining maven, joined Adobe as the Director of the Machine Learning Platform on the Adobe Sensei & Search team. Previously she was a director at Johnson Controls when she founded the AI/ML Innovation Garage. She was known as a “data doyenne” when she led the machine learning effort at the cloud company Box.

Divya Jain
In an Adobe blog post, Jain recalled that the interesting AI and ML challenges at Adobe are what drew her to join. “From what I’ve seen in the industry, Adobe is already using the state of art AI and ML deep learning models in products for real-world use cases and is much ahead in image and video analysis as compared to other companies.”
A native to India, Jain was born in a family of engineers and programmers. So it came with no surprise as she had a flair for learning new skills in computer science. After graduating from Aligarh University with a bachelor’s degree in electrical engineering, she moved to the US and obtained a master’s degree in computer engineering from San Jose State University. Also, she spent a whole year on a graduate course in data mining and analysis at Stanford University.
She has a long history working at various tech companies since then: Sun Microsystems in 2003; A startup called Kazeon Systems in 2005, which was acquired by EMC in 2009.
In 2011, Jain co-founded dLoop, a startup provides information governance ready, content management system by integrating big data analysis in the cloud. The company quickly raised attention from Box, which later acquired dLoop in 2013 and packed its whole team. Jain promptly became an engineering superstar at BOX. In 2014, she was named one of the 22 most influential female engineers in the world.
Today, she is overlooking the Adobe’s Machine Learning Platform, with the aim to enable machine learning capabilities for anybody who’s looking to implement or use them.
In the upcoming AI Frontiers Conference held from November 9 to November 11, Jain will touch upon the various challenges and emerging solutions around video summarization.
Video Summarization
With an increasing video data due to the rapid development of digital video capture and editing technology, Adobe has been witnessing a growing need for effective techniques for video retrieval and analysis. For Adobe Premiere editors, instead of watching the whole library of videos, they will prefer to view the abstract of the video and gain insights.
Video summarization is a mechanism for generating a short summary of a video. Generally, videos can be summarized by either key frames (a set of still images extracted from the video) or video skimming (a short video clip joined by either a cut or a gradual effect).
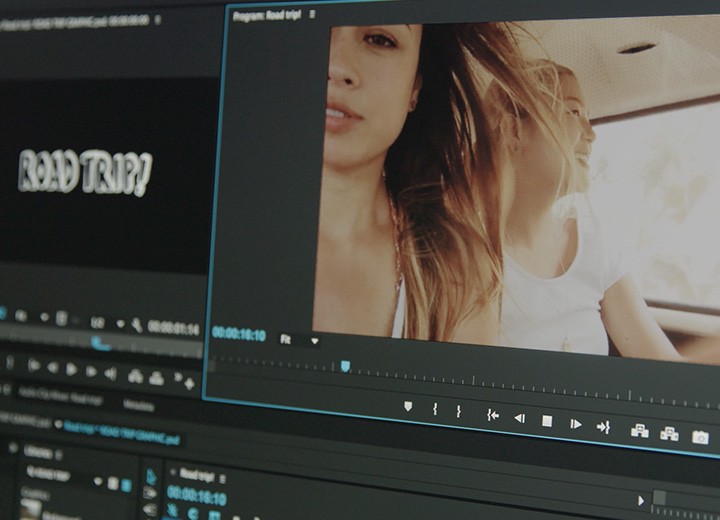
Adobe Premiere
Researchers are exploring the use of deep learning, reinforcement learning, and generative adversarial network in video summarization.
In a research paper of 2016, researchers from USC, UCLA, and UTAustin proposed a novel supervised learning technique for summarizing videos by automatically selecting keyframes. They use Long Short-Term Memory (LSTM) to model the variable-range temporal dependency among video frames, to derive both representative and short video summaries.
A paper from last year introduced an end-to-end, reinforcement learning-based framework to train a deep summarization network. The training method is fully unsupervised since labels are not required.
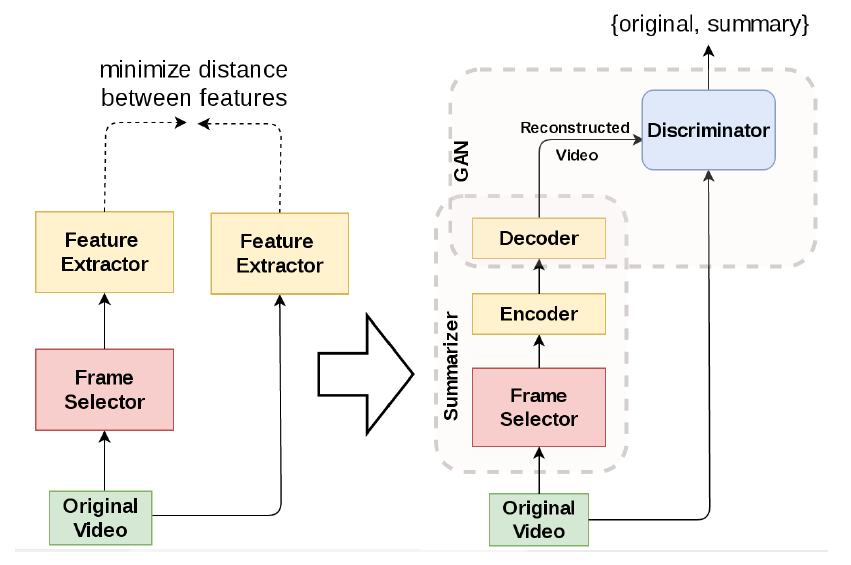
The use of GAN in video summarization is surprisingly enlightened. Last year, researchers from Oregon State University created a novel generative adversarial framework comprising a summarizer and a discriminator. The summarizer is the autoencoder LSTM to select video frames, and then decode the obtained summarization for reconstructing the input video. The discriminator is another LSTM aimed at distinguishing between the original video and its reconstruction from the summarizer. The method demonstrates a compelling performance comparing to fully supervised state-of-the-art approaches in four benchmark test.
“Deep learning and reinforcement learning is changing the landscape and emerging as the winner for optimal frame selection. Recent advances in GANs are improving the quality, aesthetics, and relevancy of the frames to represent the original videos,” said Jain. We are looking forward to hearing what Jain has to say about the role of AI in video summarization.

Divya Jain will speak at AI Frontiers Conference on Nov 9, 2018 in San Jose, California.
AI Frontiers Conference brings together AI thought leaders to showcase cutting-edge research and products. This year, our speakers include: Ilya Sutskever (Founder of OpenAI), Jay Yagnik (VP of Google AI), Kai-Fu Lee(CEO of Sinovation), Mario Munich (SVP of iRobot), Quoc Le (Google Brain), Pieter Abbeel (Professor of UC Berkeley) and more.
Get your tickets now at aifrontiers.com. For question and media inquiry, please contact: info@aifrontiers.com